)
Experten-Einstellungen für ChatGPT: Was bedeuten Temperature, Top-P und Co.?
Temperature, Top-P, Frequency- und Presence-Penalty, Max Tokens: Wir erklären verständlich, welche Stellschrauben das Verhalten von Sprachmodellen wie ChatGPT steuern – und wann welche Einstellung sinnvoll ist.
Wie funktionieren Sprachmodelle á la ChatGPT?
Sprachmodelle erzeugen Texte, indem sie vorhersagen, wie wahrscheinlich das nächste Wort bzw. die nächste Silbe ist. In der Fachsprache sind diese Textbausteine als „Tokens“ bekannt. Das Sprachmodell analysiert den bisherigen Text und wählt die Fortsetzung auf Basis von Wahrscheinlichkeiten aus.
Der gesamte Eingabetext wird dabei Silbe für Silbe erweitert. Ist ein Erweiterungsschritt abgeschlossen, wird der bis hierhin erzeugte Text erneut in das Modell eingegeben – so lange, bis das Modell selbst ein Stoppsignal sendet. In der folgenden Abbildung dient der gesamte Text „SPRACHMODELLE ERZEUGEN TEXTE,“ als Grundlage für die Berechnung der Wahrscheinlichkeit des nächsten Textbausteins.

Die Fortsetzung mit „DIE“ wurde als wahrscheinlicher eingestuft als „INDEM“. Diese Einstufung basiert auf den Trainingsdaten, mit denen das Modell trainiert wurde, und ist maßgeblich für die Ausgaben – so erhalten wir die Fortsetzung „DIE VON MENSCHEN GESCHRIEBEN ZU SEIN SCHEINEN“.

Das Modell entscheidet sich jedoch nicht immer für die wahrscheinlichste Lösung. Das verhindert, dass Texte 1:1 aus den Trainingsdaten wiedergegeben werden, und sorgt für vielfältigere Ausgaben. Hier kommen die folgenden Parameter ins Spiel, über die wir Vielfalt und Kreativität der Ausgaben steuern.
Temperature – Was bedeutet Temperature bei ChatGPT?

Die „Temperature“ kontrolliert, wie kreativ oder fokussiert die generierten Texte sind. Sie beeinflusst, welcher Textbaustein als nächstes gewählt wird, indem sie die Verteilung der Wahrscheinlichkeiten einzelner Tokens verändert.
Höhere Werte (zum Beispiel 1,5) sorgen dafür, dass unwahrscheinlichere Tokens häufiger ausgewählt werden, und machen die Ausgaben zufälliger. Eine zu hohe Temperature kann allerdings zu Halluzinationen führen, bei denen das Modell nahezu zufällige Tokens auswählt und die Ausgabe keinen Sinn mehr ergibt. Niedrigere Werte (zum Beispiel 0,2) machen die Verteilung steiler und die Ausgaben fokussierter und deterministischer.
Höhere Temperature-Werte helfen bei kreativen Schreibprojekten oder Brainstorming-Sessions. Niedrigere Werte eignen sich besser, wenn Präzision und Konsistenz wichtig sind – etwa bei professionellen E-Mails, technischen Dokumentationen oder der Analyse juristischer Dokumente.
Halluzinationen bei hohem Temperature-Wert von 1,8:

Ausgabe bei Temperature von 1,0:
Ausgabe bei Temperature von 0,2:

Top-P – Was bedeutet Top-P bei ChatGPT?

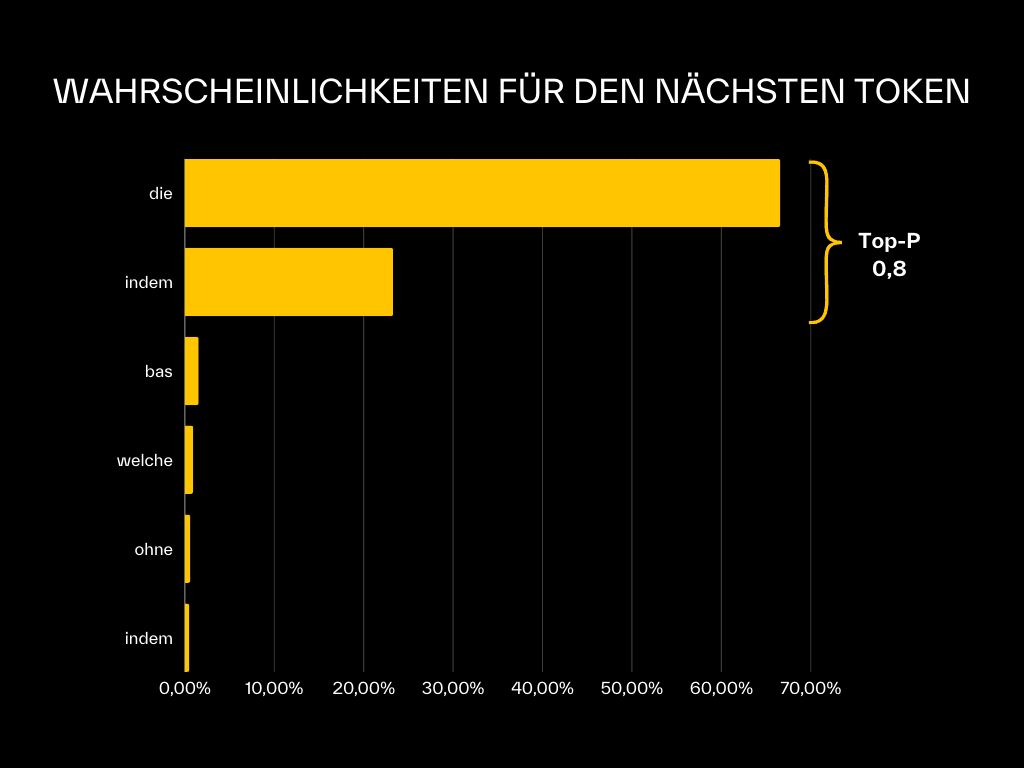
Der Top-P-Parameter steuert, welche Tokens in die engere Auswahl einbezogen werden. Betrachtet werden nur die Tokens mit der höchsten Wahrscheinlichkeit, bis deren kumulative Wahrscheinlichkeit den Top-P-Wert überschreitet. Der maximale Wert ist 1, da die Summe aller Wahrscheinlichkeiten höchstens 100 % beträgt. Ein Top-P von 0,8 bedeutet, dass nur die Tokens berücksichtigt werden, die zusammen 80 % der höchsten Wahrscheinlichkeit ergeben – im Beispiel „DIE“ und „INDEM“. Andere Tokens fallen aus der Auswahl.
Das ist insbesondere relevant, wenn Sie mit einer hohen Temperature arbeiten, um kreativere Ergebnisse zu erzielen: Über Top-P lassen sich unbrauchbare Resultate herausfiltern, ohne die Kreativität zu reduzieren. In Kombination mit einer hohen Temperature sollte der Parameter daher abgesenkt werden, um weiterhin sinnvolle Ausgaben zu erzeugen.
Wahrscheinlichkeitsverteilung für den nächsten Textbaustein mit Top-P 0,8:
Was bedeuten Frequency Penalty und Presence Penalty bei ChatGPT?
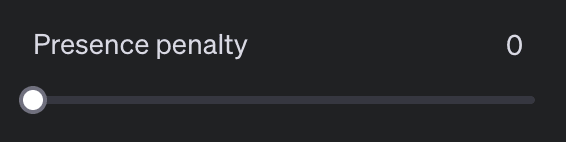
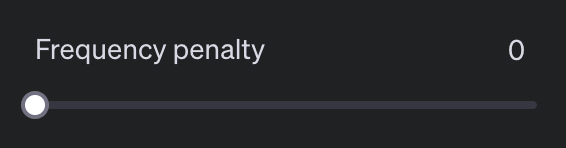
Frequency Penalty und Presence Penalty fördern vielfältigere und kreativere Texte, indem sie das Modell anregen, neue Themen und Wörter einzuführen.
Die Frequency Penalty reguliert die Wahrscheinlichkeit, dass das Modell häufig vorkommende Wörter wiederholt: Je öfter ein Textbaustein bereits vorkommt, desto unwahrscheinlicher wird ein weiteres Vorkommen. Die Presence Penalty hingegen reduziert die Wahrscheinlichkeit, Wörter erneut zu verwenden, die bereits vorkommen – hier wird schon das einmalige Vorkommen bestraft, nicht erst die Häufigkeit. Beide Parameter können Werte zwischen 0 und 2 annehmen.
Ein höherer Wert fördert selten genutzte oder neue Wörter und damit vielfältigere Texte; ein niedrigerer Wert führt zu häufigerer Verwendung gängiger Wörter. Typischerweise werden Werte um 0,1 genutzt, um Wiederholungen leicht zu reduzieren. Sehr hohe Werte können die Textqualität stark beeinträchtigen.
Max Tokens – Wie stelle ich die Länge der Antworten ein?
„Max Tokens“ legt fest, wie viele Tokens das Modell maximal in einer Antwort generieren darf. Ein Token entspricht grob einer Silbe. Ist der Wert zu niedrig, werden Antworten abgeschnitten; ist er zu hoch, entstehen unnötig lange Antworten. Über diesen Parameter lassen sich bei API-Nutzung auch Kosten steuern, da nach generierten Tokens abgerechnet wird.
Optimale Einstellung der Parameter
Für kreative Texte:
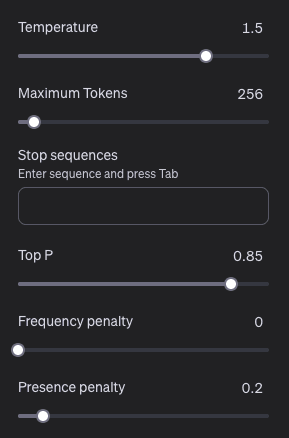
Bei kreativen Texten – etwa zum Brainstorming – sollten Temperature und Frequency Penalty erhöht und Top-P abgesenkt werden. Max Tokens nach Bedarf justieren, um unnötige Kosten zu vermeiden.
Für neutrale, fachliche Inhalte:
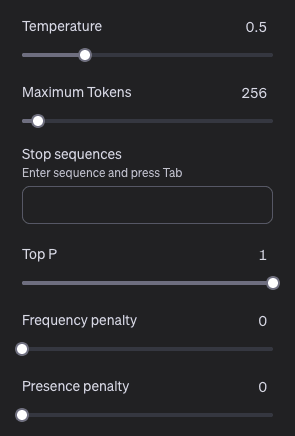
Hier bietet es sich an, die Parameter eher auf den Standardeinstellungen zu belassen und den Temperature-Wert nach unten zu korrigieren. Das ist die richtige Wahl, wenn es – wie in der juristischen Arbeit – auf Genauigkeit und Nachvollziehbarkeit ankommt.
Fazit
Es ist sinnvoll, die beschriebenen Parameter im Zuge der konkreten Aufgabe zu justieren, bis die Ausgaben überzeugen. Wer versteht, wie Temperature, Top-P und Co. wirken, setzt Sprachmodelle gezielter und sicherer ein. Genau auf dieser Kontrolle baut PyleHound auf: Für die juristische Analyse sind die Modellparameter so gewählt, dass Präzision und Belegbarkeit Vorrang vor Kreativität haben.
)